Update: New low-latency database engine is live
July 28, 2018
With weary coding fingertips I type to let you know that a very long week has paid off.
More profiling of the bedraggled Server1, which has the largest map data set of any server, revealed that file IO inefficiencies in the custom-coded StackDB were to blame. StackDB was designed to quickly answer questions about recently-accessed map cells---assuming that people in cities are often looking at the same stuff, so that stuff should be kept near the top of the stack. The old off-the-shelf KissDB did not do that, meaning that the newest stuff was the slowest to access as the data set grew.
However, none of these optimizations addressed what is actually the most common case: asking about a map cell that isn't in the database at all. When you wander around in the wilderness and look at the empty ground, we have to ask the database to confirm that that patch of ground is indeed empty. Maybe someone visited that spot earlier and dropped something there that you should see.
It turns out that in both KissDB and StackDB, this is the slowest operation of all. A non-existent cell can never be at the top of the stack, because it doesn't exist, which means that we need to walk to the bottom of the stack to find out for sure that it doesn't exist.
Finally, KissDB and StackDB are both hash table systems, but both of them use fixed size hash tables. In the case of Server1, there were 15 million data records crammed into an 80,000 slot hash table. This means lots of pages to look through in each slot (KissDB) or deep stacks to wade to the bottom of (StackDB) to find out that a given map cell really isn't there, and therefore is empty.
Even worse, the architecture of both engines requires loads of random-access disk seeks to move through the pages or the stack. And disk seeks are extremely slow, relatively speaking, especially when they are jumping around a huge file and missing the cache over and over.
LinearDB, my latest custom-coded database engine, has an ever-expanding hash table based on a very clever algorithm---which I did not invent---called Linear Hashing. The hash table grows gradually along with the data, essentially never letting it get too many layers deep. In addition, a kind of "mini map" of data fingerprints is kept in RAM, allowing us to ask questions about map cells that don't exist without touching the disk at all.
The performance gains here are pretty astounding.
On a simple benchmark where a single player walks in a straight line through the wilderness for a minute, the old database engine performed 1.9 million disk seeks and 3.8 million disk reads.
During the same single-player journey, the new database engine performs less than 4700 seeks and 1600 reads.
Yes, that's a 427x and 2400x in disk seeks and reads, respectively.
According to a system call time profiler, this results in approximately 180x less time spent waiting for the disk. In other words, this part of the server is now one hundred and eighty times faster than it used to be.
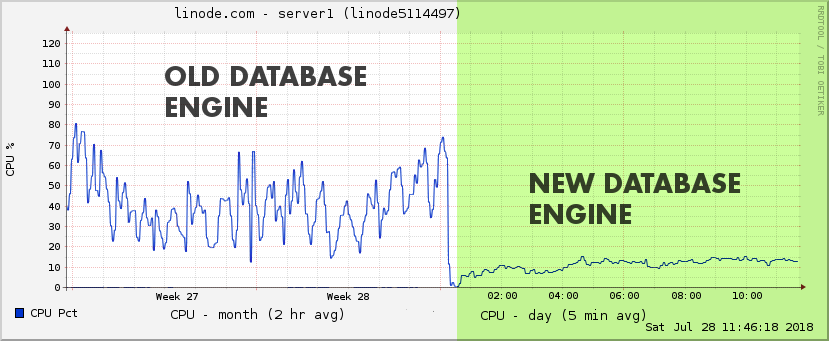
Server1 is the only server that has this new engine installed so far. It has the biggest data sets and was seeing the most lag with the old database, so it's the best server to stress test with. It's now back in circulation at the top of the list and seems to be lag-free. I'll be incrementally increasing the player cap over the next few days and seeing how it handles the load.
Assuming that all goes well, I will be rolling the new database engine out to the other servers next week. The end of server lag is almost in sight.
A big thanks goes out to sc0rp, who spent many hours discussing the intricacies of these systems with me in the forums, and filled my head with all sorts of great ideas. I had never even heard of linear hashing until sc0rp told me about it.
|
|
|